
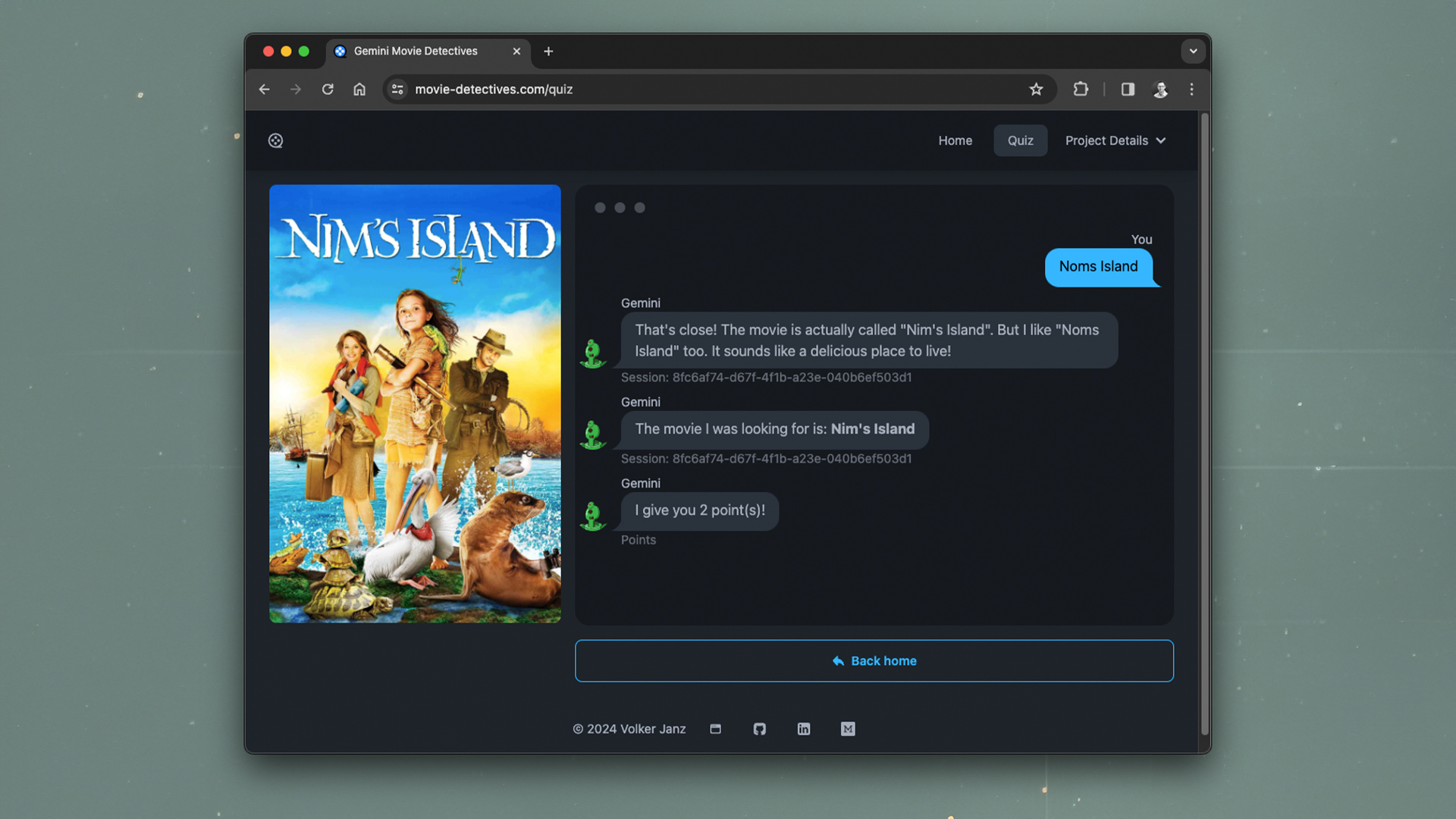
![]()
Gemini Movie Detectives is a project aimed at leveraging the power of the Gemini Pro model via VertexAI to create an engaging quiz game using the latest movie data from The Movie Database (TMDB). But it is more than just a movie quiz, it represents a gateway to AI-driven educational content in schools and universities, making the combination of education and gaming approachable.
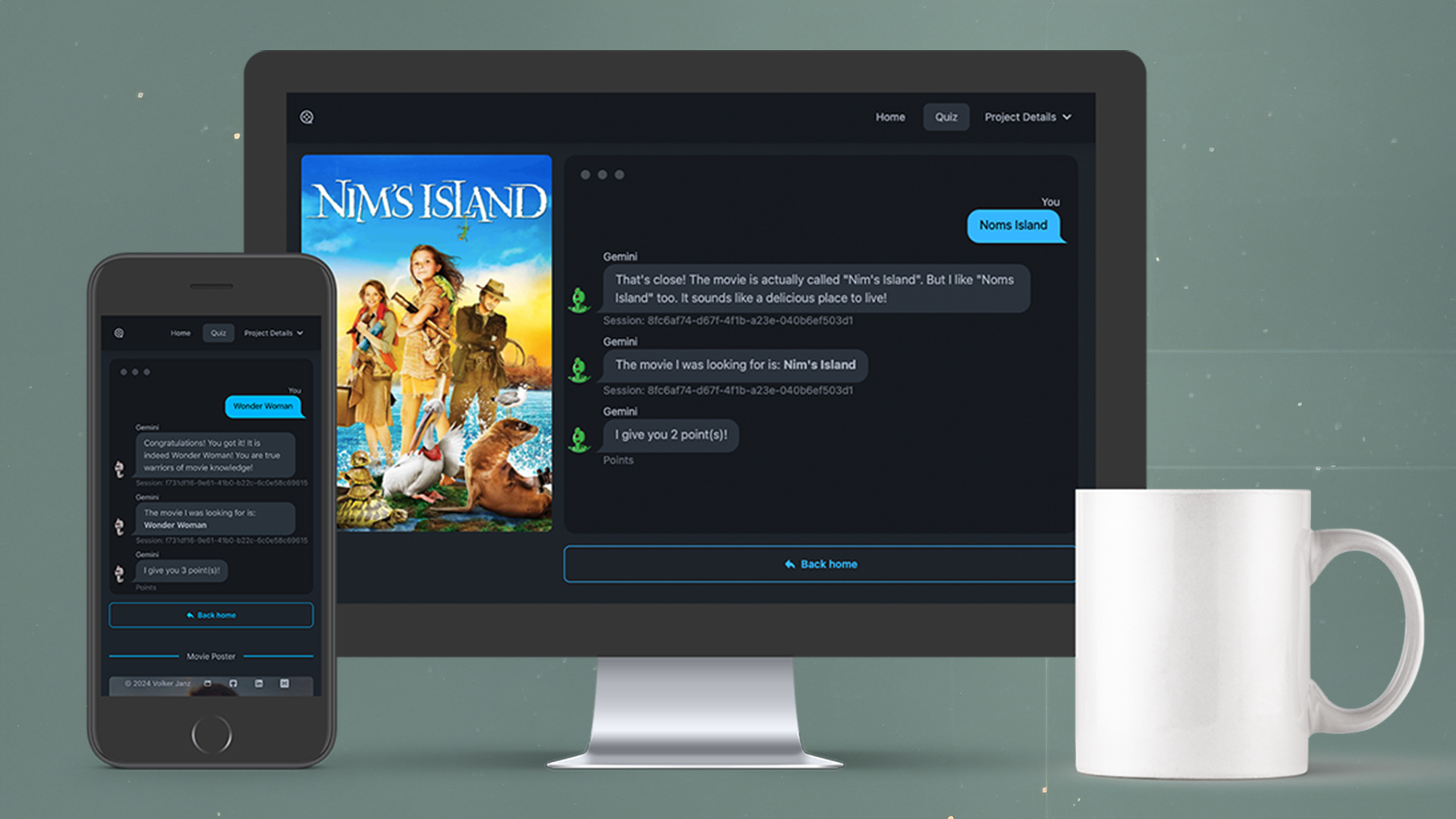
Part of the project was also to make it deployable and to create a live version. Try it yourself: movie-detectives.com
Keep in mind: this is a prototype. I also applied various limits to control GCP costs. In case of exceptions, get a coffee and try again ☕️.
The project uses 2 separate repositories:
- Github repository for backend: https://github.com/vojay-dev/gemini-movie-detectives-api
- Github repository for frontend: https://github.com/vojay-dev/gemini-movie-detectives-ui
tl;dr for the Judges: I added instructions for you for local testing as the very last chapter ⬇️
📚 I also wrote a blog article that explains all the underlying concepts in more detail:
💡 Inspiration
Growing up as a passionate gamer and now working as a Data Engineer, I've always been drawn to the intersection of gaming and data. With this project, I combined two of my greatest passions: gaming and data. Back in the 90' I always enjoyed the video game series You Don't Know Jack, a delightful blend of trivia and comedy that not only entertained but also taught me a thing or two. Generally, the usage of games for educational purposes is another concept that fascinates me.
In 2023, I organized a workshop to teach kids and young adults game development. They learned about mathematical concepts behind collision detection, yet they had fun as everything was framed in the context of gaming. It was eye-opening that gaming is not only a huge market but also holds a great potential for knowledge sharing.
With this project, called Movie Detectives, I aim to showcase the magic of Gemini, and AI in general, in crafting engaging trivia and educational games, but also how game design can profit from these technologies in general.
By feeding the Gemini LLM with accurate and up-to-date movie metadata, I could ensure the accuracy of the questions from Gemini. An important aspect, because without this Retrieval-Augmented Generation (RAG) methodology to enrich queries with real-time metadata, there's a risk of propagating misinformation – a typical pitfall when using AI for this purpose.
Another game-changer lies in the modular prompt generation framework I've crafted using Jinja templates. It's like having a Swiss Army knife for game design – effortlessly swapping show master personalities to tailor the game experience. And with the language module, translating the quiz into multiple languages is a breeze, eliminating the need for costly translation processes.
Taking that on a business perspective, it can be used to reach a much broader audience of customers, without the need of expensive translation processes.
From a business standpoint, this modularization opens doors to a wider customer base, transcending language barriers without breaking a sweat. And personally, I've experienced firsthand the transformative power of these modules. Switching from the default quiz master to the dad-joke-quiz-master was a riot – a nostalgic nod to the heyday of You Don't Know Jack, and a testament to the versatility of this project.
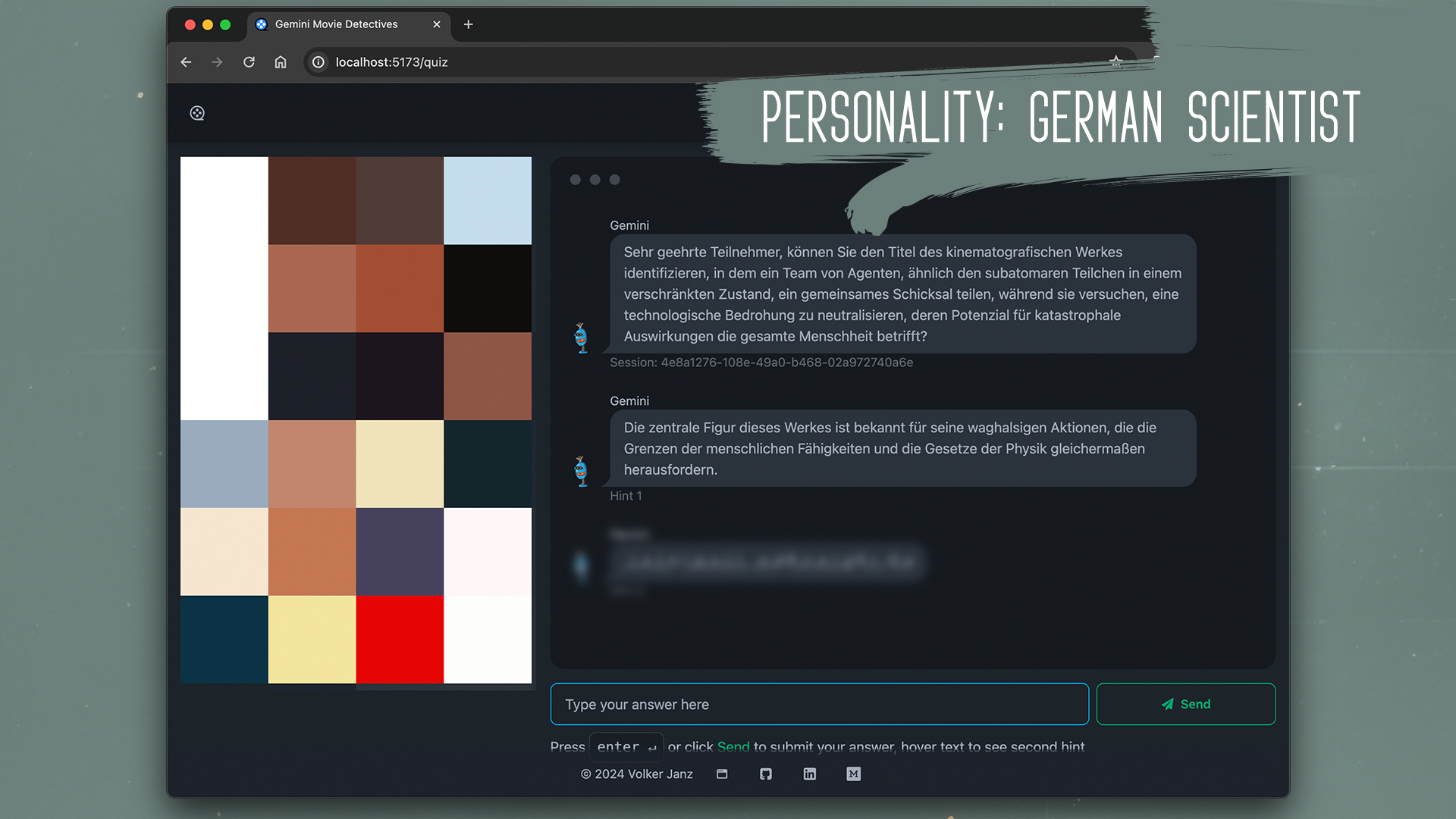
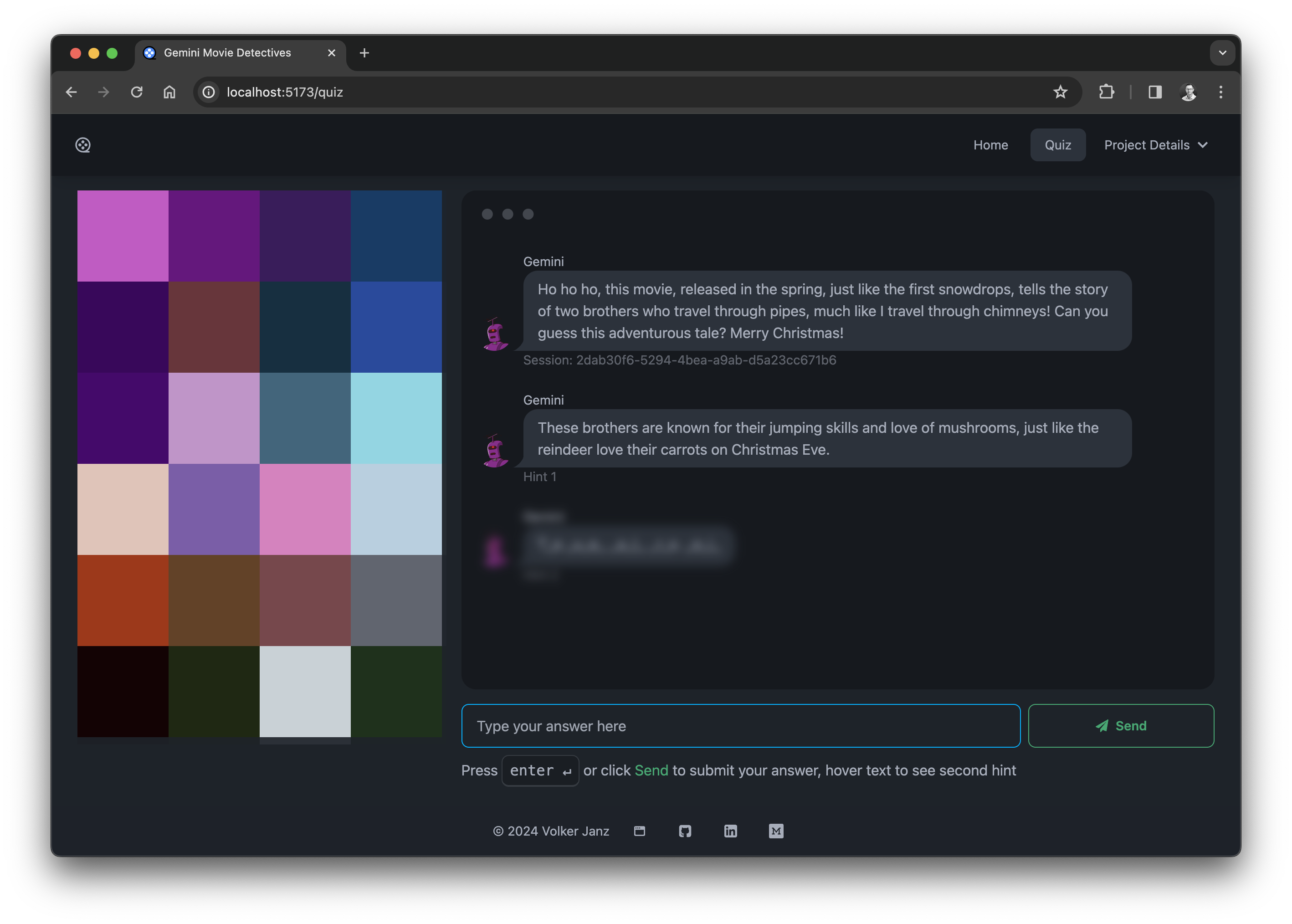 Movie Detectives - Example: Santa Claus personality
Movie Detectives - Example: Santa Claus personality
🎮 What it does
Essentially, the application fetches up-to-date movie metadata from an external API (TMDB), constructs a prompt based on different modules (personality, language, ...), enriches this promt with the metadata and that way, uses Gemini to initate a movie quiz in which the user has to guess the correct title.
Backend
The backend infrastructure is built with FastAPI and Python, employing the Retrieval-Augmented Generation (RAG) methodology to enrich queries with real-time metadata. Utilizing Jinja templating, the backend modularizes prompt generation into base, personality, and data enhancement templates, enabling the generation of accurate and engaging quiz questions.
Frontend
The frontend is powered by Vue 3 and Vite, supported by daisyUI and Tailwind CSS for efficient frontend development. Together, these tools provide users with a sleek and modern interface for seamless interaction with the backend.
Summary
In Movie Detectives, quiz answers are interpreted by the Language Model (LLM) once again, allowing for dynamic scoring and personalized responses. This showcases the potential of integrating LLM with RAG in game design and development, paving the way for truly individualized gaming experiences. Furthermore, it demonstrates the potential for creating engaging quiz trivia or educational games by involving LLM. Adding and changing personalities or languages is as easy as adding more Jinja template modules. With very little effort, this can change the full game experience, reducing the effort for developers. Try it yourself and change the AI personality in the quiz configuration.
⚙️ How it was built
Tech stack
Backend
- Python 3.12 + FastAPI API development
- httpx for TMDB integration
- Jinja templating for modular prompt generation
- Pydantic for data modeling and validation
- Poetry for dependency management
- Docker for deployment
- TMDB API for movie data
- VertexAI and Gemini for generating quiz questions and evaluating answers
- Ruff as linter and code formatter together with pre-commit hooks
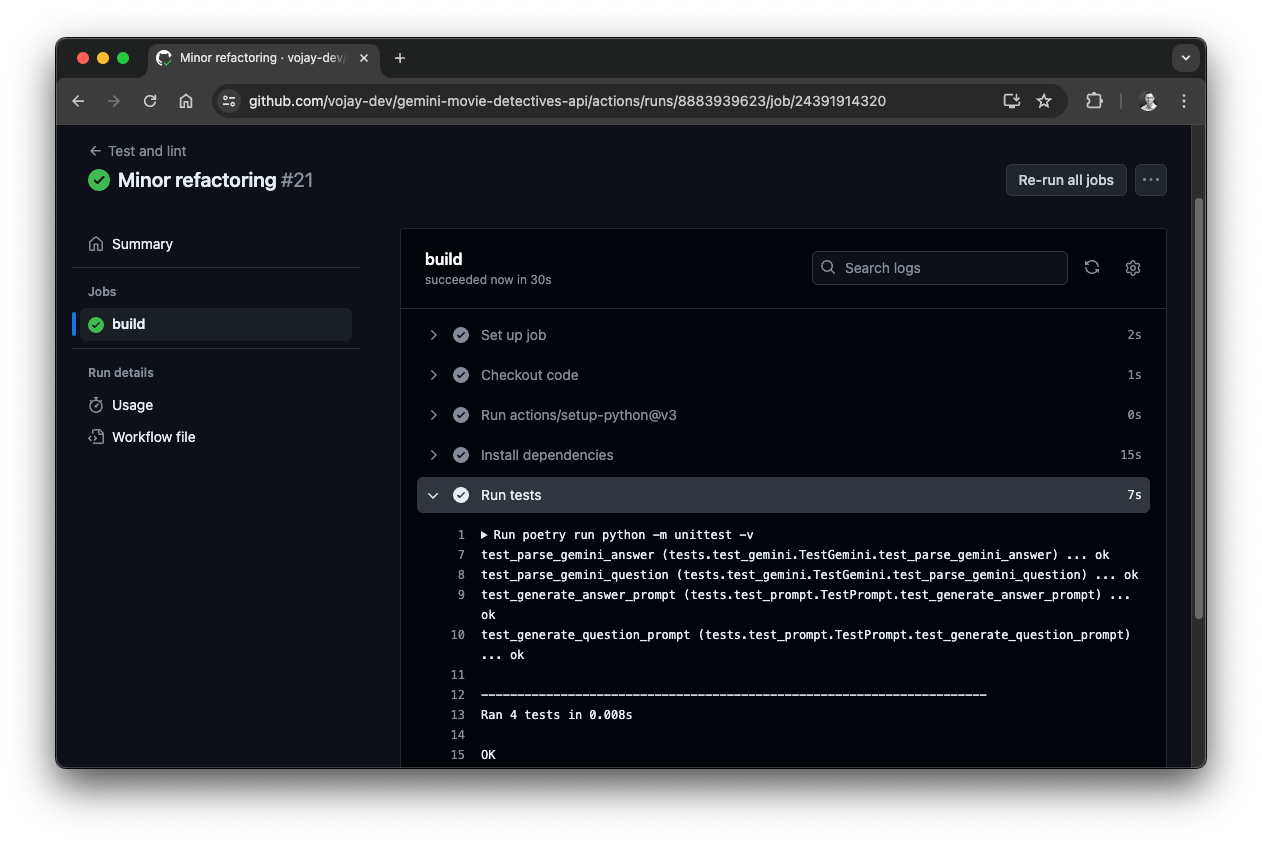
- Github Actions to automatically run tests and linter on every push
Frontend
System overview
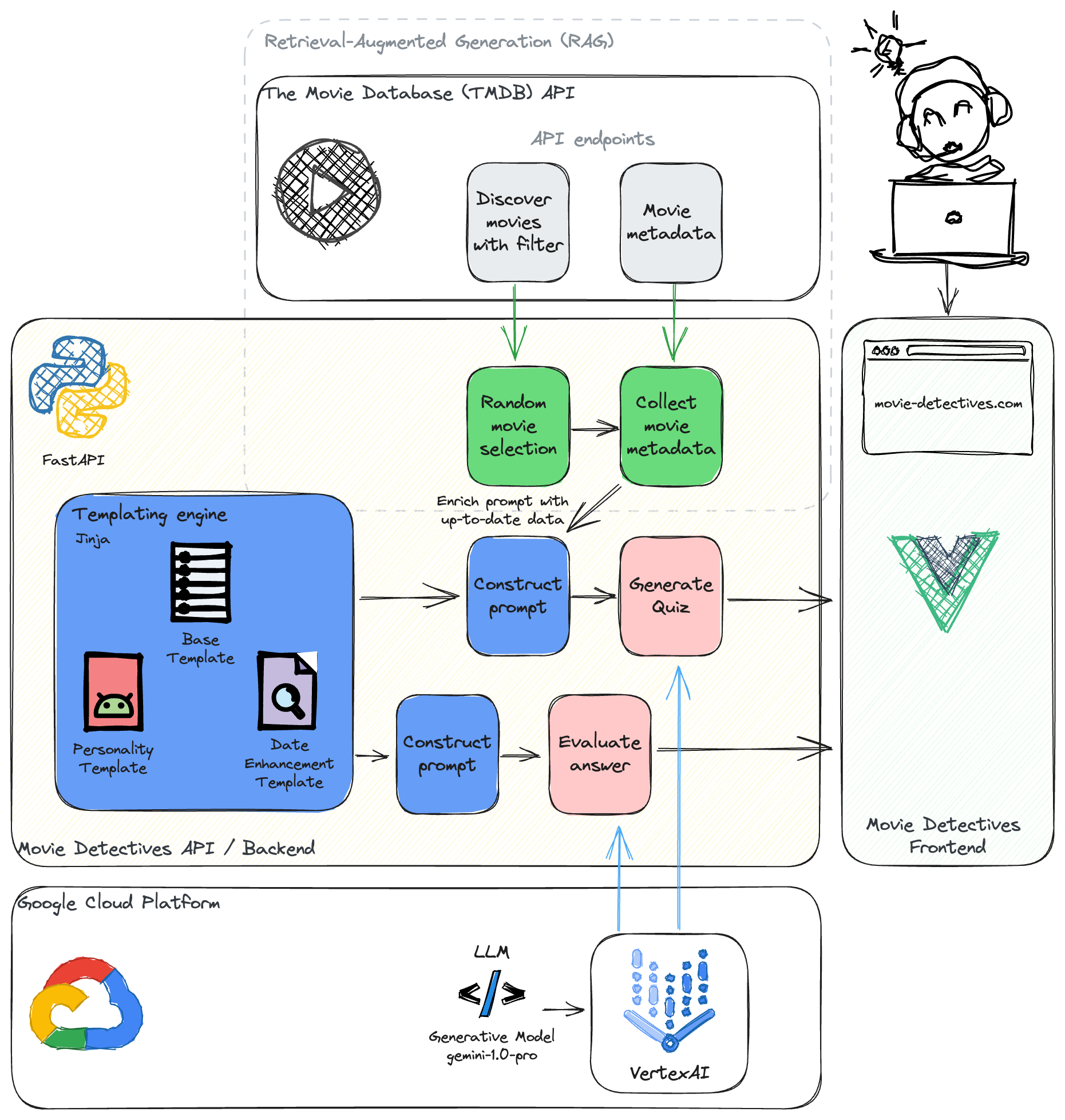 Movie Detectives - System Overview
Movie Detectives - System Overview
As can be seen in the overview, Retrieval-Augmented Generation (RAG) is one of the essential ideas of the backend. Let's have a closer look at this particular paradigm.
Understanding Retrieval-Augmented Generation (RAG)
In the realm of Large Language Models (LLM) and AI, one paradigm becoming more and more popular is Retrieval-Augmented Generation (RAG). But what does RAG entail, and how does it influence the landscape of AI development?
At its essence, RAG enhances LLM systems by incorporating external data to enrich their predictions. Which means, you pass relevant context to the LLM as an additional part of the prompt, but how do you find relevant context? Usually, this data can be automatically retrieved from a database with vector search or dedicated vector databases. Vector databases are especially useful, since they store data in a way, so that it can be queried for similar data quickly. The LLM then generates the output based on both, the query and the retrieved documents.
Picture this: you have an LLM capable of generating text based on a given prompt. RAG takes this a step further by infusing additional context from external sources, like up-to-date movie data, to enhance the relevance and accuracy of the generated text.
Let's break down the key components of RAG:
- LLMs: LLMs serve as the backbone of RAG workflows. These models, trained on vast amounts of text data, possess the ability to understand and generate human-like text.
- Vector Indexes for contextual enrichment: A crucial aspect of RAG is the use of vector indexes, which store embeddings of text data in a format understandable by LLMs. These indexes allow for efficient retrieval of relevant information during the generation process. In the context of the project this could be a database of movie metadata.
- Retrieval process: RAG involves retrieving pertinent documents or information based on the given context or prompt. This retrieved data acts as the additional input for the LLM, supplementing its understanding and enhancing the quality of generated responses. This could be getting all relevant information known and connected to a specific movie.
- Generative Output: With the combined knowledge from both the LLM and the retrieved context, the system generates text that is not only coherent but also contextually relevant, thanks to the augmented data.
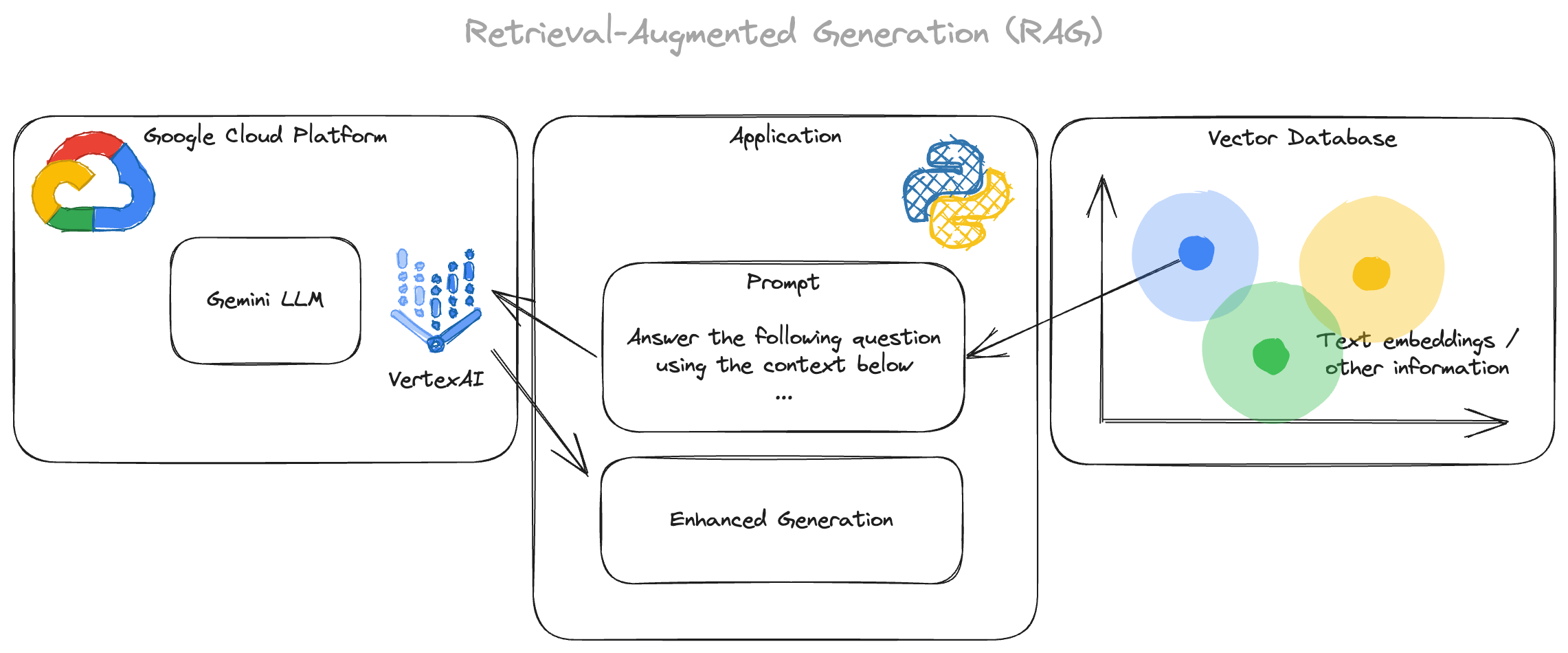
While in the Gemini Movie Detectives project, the prompt is enhanced with external API data from The Movie Database, RAG typically involves the use of vector indexes to streamline this process. It is using much more complex documents as well as a much higher amount of data for enhancement. Thus, these indexes act like signposts, guiding the system to relevant external sources quickly.
In this project, it is therefore a mini version of RAG but showing the basic idea at least, demonstrating the power of external data to augment LLM capabilities.
In more general terms, RAG is a very important concept, especially when crafting trivia quizzes or educational games using LLMs like Gemini. This concept can avoid the risk of false positives, asking wrong questions, or misinterpreting answers from the users.
Here are some open-source projects that might be helpful when approaching RAG in one of your projects:
- txtai: All-in-one open-source embeddings database for semantic search, LLM orchestration and language model workflows.
- LangChain: LangChain is a framework for developing applications powered by large language models (LLMs).
- Qdrant: Vector Search Engine for the next generation of AI applications.
- Weaviate: Weaviate is a cloud-native, open source vector database that is robust, fast, and scalable.
Of course, with the potential value of this approach for LLM-based applications, there are many more open- and close-source alternatives, but with these, you should be able to get your research on the topic started.
Main components
Backend
Github repository for backend: https://github.com/vojay-dev/gemini-movie-detectives-api
One of the main challenges with todays AI/ML projects is data quality. But that does not only apply to ETL/ELT pipelines, which prepare datasets to be used in model training or prediction, but also to the AI/ML application itself. Using Python for example usually enables Data Engineers and Scientist to get a reasonable result with little code but being (mostly) dynamically typed, Python lacks of data validation when used in a naive way.
That is why in this project, I combined FastAPI with Pydantic, a powerful data validation library for Python. The goal was to make the API lightweight but strict and strong, when it comes to data quality and validation. Instead of plain dictionaries for example, the Movie Detectives API strictly uses custom classes inherited from the BaseModel provided by Pydantic. This is the configuration for a quiz for example:
class QuizConfig(BaseModel):
vote_avg_min: float = Field(5.0, ge=0.0, le=9.0)
vote_count_min: float = Field(1000.0, ge=0.0)
popularity: int = Field(1, ge=1, le=3)
personality: str = Personality.DEFAULT.name
language: str = Language.DEFAULT.name
This example illustrates, how not only correct type is ensured, but also further validation is applied to the actual values.
Furthermore, up-to-date Python features, like StrEnum are used to distinguish certain types, like personalities:
class Personality(StrEnum):
DEFAULT = 'default.jinja'
CHRISTMAS = 'christmas.jinja'
SCIENTIST = 'scientist.jinja'
DAD = 'dad.jinja'
Also, duplicate code is avoided by defining custom decorators. For example, the following decorator limits the number of quiz sessions today, to have control over GCP costs:
call_count = 0
last_reset_time = datetime.now()
def rate_limit(func: callable) -> callable:
@wraps(func)
def wrapper(*args, **kwargs) -> callable:
global call_count
global last_reset_time
# reset call count if the day has changed
if datetime.now().date() > last_reset_time.date():
call_count = 0
last_reset_time = datetime.now()
if call_count >= settings.quiz_rate_limit:
raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST, detail='Daily limit reached')
call_count += 1
return func(*args, **kwargs)
return wrapper
It is then simply applied to the related API function:
@app.post('/quiz')
@rate_limit
@retry(max_retries=settings.quiz_max_retries)
async def start_quiz(quiz_config: QuizConfig = QuizConfig()):
The combination of up-to-date Python features and libraries, such as FastAPI, Pydantic or Ruff makes the backend less verbose but still very stable and ensures a certain data quality, to ensure the LLM output has the expected quality.
Configuration
Prerequisite
- TMDB API key (can be generated for free)
- GCP project with VertexAI API enabled
- JSON credentials file for GCP Service Account with VertexAI permissions
The API is configured via environment variables. If a .env file is present in the project root, it will be loaded automatically. The following variables must be set:
TMDB_API_KEY: The API key for The Movie Database (TMDB).GCP_PROJECT_ID: The ID of the Google Cloud Platform (GCP) project used for VertexAI and Gemini.GCP_LOCATION: The location used for prediction processes.GCP_SERVICE_ACCOUNT_FILE: The path to the service account file used for authentication with GCP.
There are more config variables with defaults, which can be used to adjust the default API behavior.
This is implemented using the pydantic_settings module:
class Settings(BaseSettings):
model_config = SettingsConfigDict(env_file='.env', env_file_encoding='utf-8')
tmdb_api_key: str
gcp_gemini_model: str = 'gemini-1.0-pro'
gcp_project_id: str
gcp_location: str
gcp_service_account_file: str
quiz_rate_limit: int = 100
quiz_max_retries: int = 10
That way, it is also easy to change the Gemini model used for predictions. For example: if you would like to try the Gemini Experimental model, simply set an environment variable GCP_GEMINI_MODEL to gemini-experimental.
Gemini Client
Using Gemini from Google with Python via VertexAI starts by adding the necessary dependency to the project:
poetry add 'google-cloud-aiplatform>=1.38'
With that, you can import and initialize vertexai with your JSON key file. Also you can load a model, like the newly released Gemini 1.5 Pro model, and start a chat session like this:
import vertexai
from google.oauth2.service_account import Credentials
from vertexai.generative_models import GenerativeModel
project_id = "my-project-id"
location = "us-central1"
credentials = Credentials.from_service_account_file("credentials.json")
model = "gemini-1.0-pro"
vertexai.init(project=project_id, location=location, credentials=credentials)
model = GenerativeModel(model)
chat_session = model.start_chat()
You can now use chat.send_message() to send a prompt to the model. However, since you get the response in chunks of data, I use a little helper function, so that you simply get the full response as one String:
def get_chat_response(chat: ChatSession, prompt: str) -> str:
text_response = []
responses = chat.send_message(prompt, stream=True)
for chunk in responses:
text_response.append(chunk.text)
return ''.join(text_response)
A full example can then look like this:
import vertexai
from google.oauth2.service_account import Credentials
from vertexai.generative_models import GenerativeModel, ChatSession
project_id = "my-project-id"
location = "us-central1"
credentials = Credentials.from_service_account_file("credentials.json")
model = "gemini-1.0-pro"
vertexai.init(project=project_id, location=location, credentials=credentials)
model = GenerativeModel(model)
chat_session = model.start_chat()
def get_chat_response(chat: ChatSession, prompt: str) -> str:
text_response = []
responses = chat.send_message(prompt, stream=True)
for chunk in responses:
text_response.append(chunk.text)
return ''.join(text_response)
response = get_chat_response(
chat_session,
"How to say 'you are awesome' in Spanish?"
)
print(response)
Running this, Gemini gave me the following response:
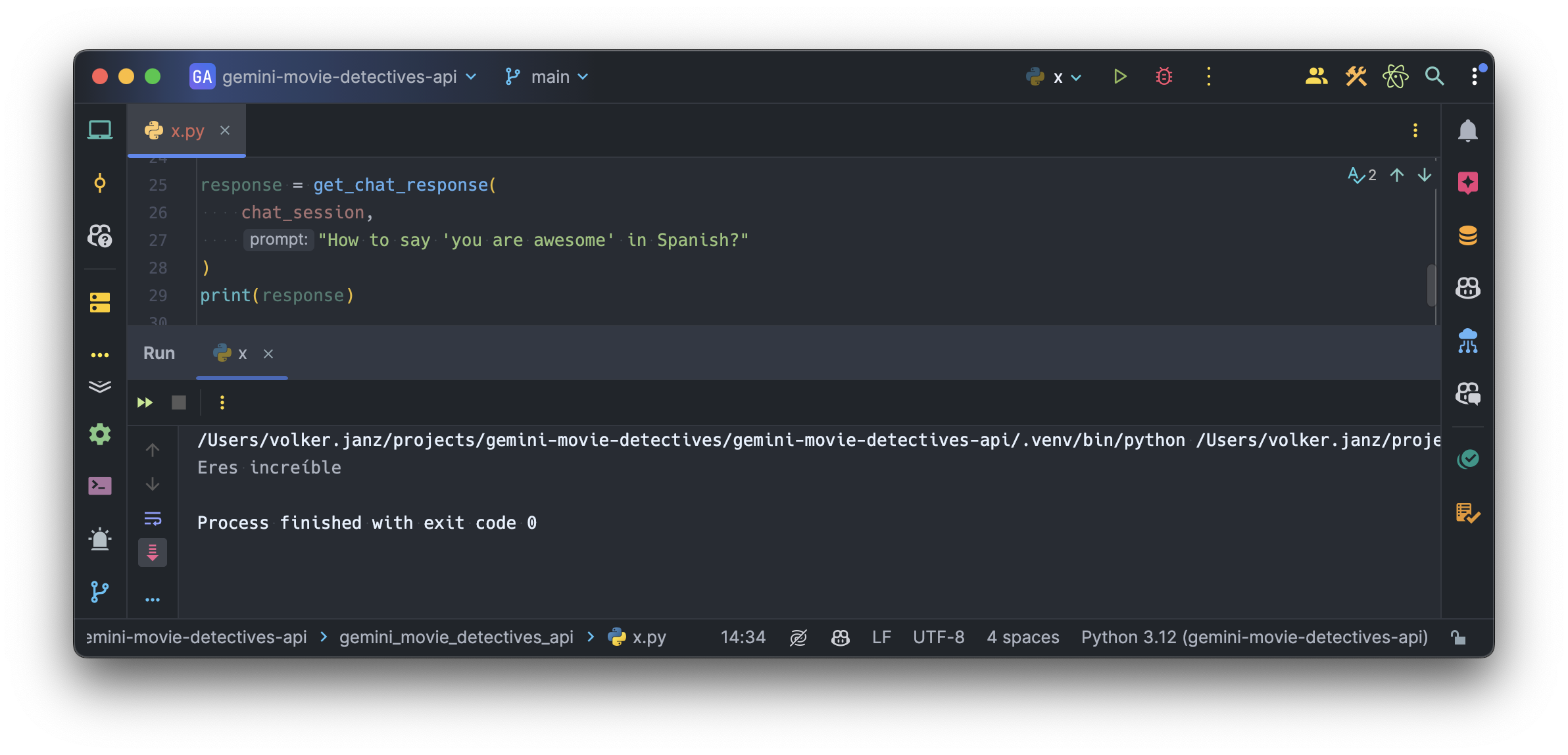 You are awesome
You are awesome
I agree with Gemini:
Eres increíble
Another hint when using this: you can also configure the model generation by passing a configuration to the generation_config parameter as part of the send_message function. For example:
generation_config = {
'temperature': 0.5
}
responses = chat.send_message(
prompt,
generation_config=generation_config,
stream=True
)
I am using this in Gemini Movie Detectives to set the temperature to 0.5, which gave me best results. In this context temperature means: how creative are the generated responses by Gemini. The value must be between 0.0 and 1.0, whereas closer to 1.0 means more creativity.
One of the main challenges apart from sending a prompt and receive the reply from Gemini is to parse the reply in order to extract the relevant information.
One learning from the project is:
Specify a format for Gemini, which does not rely on exact words but uses key symbols to separate information elements
For example, the question prompt for Gemini contains this instruction:
Your reply must only consist of three lines! You must only reply strictly using the following template for the three lines:
Question: <Your question>
Hint 1: <The first hint to help the participants>
Hint 2: <The second hint to get the title more easily>
The naive approach would be, to parse the answer by looking for a line that starts with Question:. However, if we use another language, like German, the reply would look like: Antwort:.
Instead, focus on the structure and key symbols. Read the reply like this:
- It has 3 lines
- The first line is the question
- Second line the first hint
- Third line the second hint
- Key and value are separated by
:
With this approach, the reply can be parsed language agnostic, and this is my implementation in the actual client:
@staticmethod
def parse_gemini_question(gemini_reply: str) -> GeminiQuestion:
result = re.findall(r'[^:]+: ([^\n]+)', gemini_reply, re.MULTILINE)
if len(result) != 3:
msg = f'Gemini replied with an unexpected format. Gemini reply: {gemini_reply}'
logger.warning(msg)
raise ValueError(msg)
question = result[0]
hint1 = result[1]
hint2 = result[2]
return GeminiQuestion(question=question, hint1=hint1, hint2=hint2)
In the future, the parsing of responses will become even easier. During the Google Cloud Next '24 conference, Google announced that Gemini 1.5 Pro is now publicly available and with that, they also announced some features including a JSON mode to have responses in JSON format. Checkout this article for more details.
Apart from that, I wrapped the Gemini client into a configurable class. You can find the full implementation open-source on Github.
TMDB Client
The TMDB Client class is using httpx to perform requests against the TMDB API.
httpx is a rising star in the world of Python libraries. While requests has long been the go-to choice for making HTTP requests, httpx offers a valid alternative. One of its key strengths is asynchronous functionality. httpx allows you to write code that can handle multiple requests concurrently, potentially leading to significant performance improvements in applications that deal with a high volume of HTTP interactions. Additionally, httpx aims for broad compatibility with requests, making it easier for developers to pick it up.
In case of Gemini Movie Detectives, there are two main requests:
get_movies: Get a list of random movies based on specific settings, like average number of votesget_movie_details: Get details for a specific movie to be used in a quiz
In order to reduce the amount of external requests, the latter one uses the lru_cache decorator, which stands for "Least Recently Used cache". It's used to cache the results of function calls so that if the same inputs occur again, the function doesn't have to recompute the result. Instead, it returns the cached result, which can significantly improve the performance of the program, especially for functions with expensive computations. In our case, we cache the details for 1024 movies, so if 2 players get the same movie, we do not need to make a request again:
@lru_cache(maxsize=1024)
def get_movie_details(self, movie_id: int):
response = httpx.get(f'https://api.themoviedb.org/3/movie/{movie_id}', headers={
'Authorization': f'Bearer {self.tmdb_api_key}'
}, params={
'language': 'en-US'
})
movie = response.json()
movie['poster_url'] = self.get_poster_url(movie['poster_path'])
return movie
Accessing data from The Movie Database (TMDB) is for free for non-commercial usage, you can simply generate an API key and start makeing requests.
Prompt Generator
The Prompt Generator is a class wich combines and renders Jinja2 template files to create a modular prompt.
Jinja2 is a template engine for Python. Jinja2 facilitates the creation of dynamic content across various domains. It separates logic from presentation, allowing for clean and maintainable codebases.
It uses the following core concepts:
- Templates: Text files containing content specific to the use case (e.g., HTML, configuration files, SQL queries).
- Environment: Manages template configuration (e.g., delimiters, autoescaping).
- Variables: Inserted into templates using double curly braces (
{{ variable }}). - Blocks: Defined with
{% ... %}tags for control flow (e.g., loops, conditionals). - Comments: Enclosed in
{# ... #}for code readability.
Even though Jinja2 is often used in web development, since it enables the creation of dynamic content, it is also used for other cases like Airflow.
In this project, it is used to define templates to make the prompt generation modular. That way, our Python code is kept clean and we have a modular solution that can easily be extended.
There are two base templates: one for generating the question and one for evaluating the answer. Apart from that, there is a metadata template to enrich the prompt with up-to-date movie data. Furthermore, there are language and personality templates, organized in separate folders with a template file for each option.
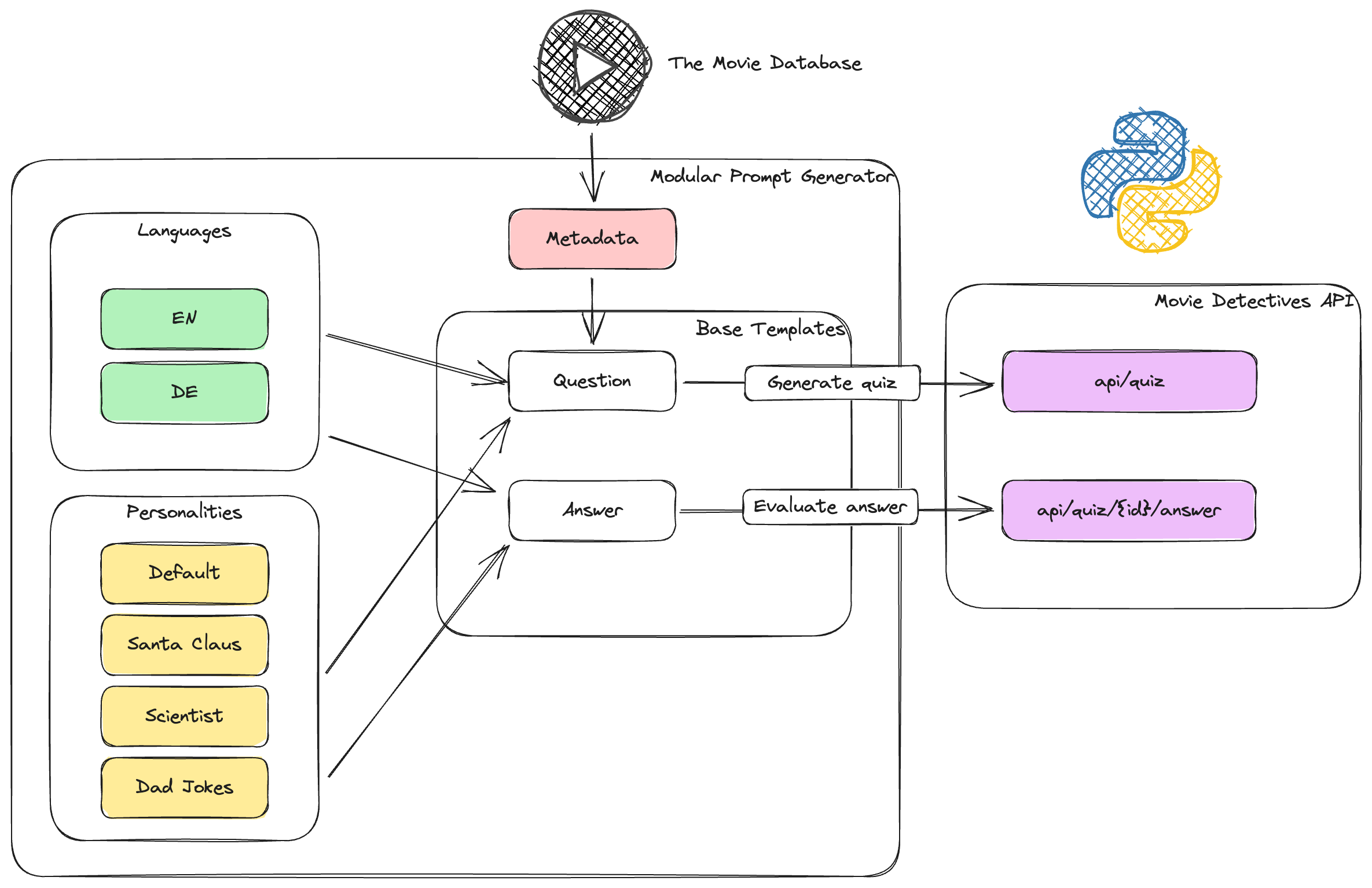 Movie Detectives - Prompt Generator
Movie Detectives - Prompt Generator
Using Jinja2 allows to have advanced features like template inheritance, which is used for the metadata for example:
{% include 'metadata.jinja' %}
This makes it easy to extend this component, not only with more options for personalities and languages, but also to extract it into its own open-source project to make it available for other Gemini projects.
Frontend
Github repository for frontend: https://github.com/vojay-dev/gemini-movie-detectives-ui
The Movie Detectives frontend is split into four main components and uses vue-router to navigate between them.
Home
The Home component simply displays the welcome message.
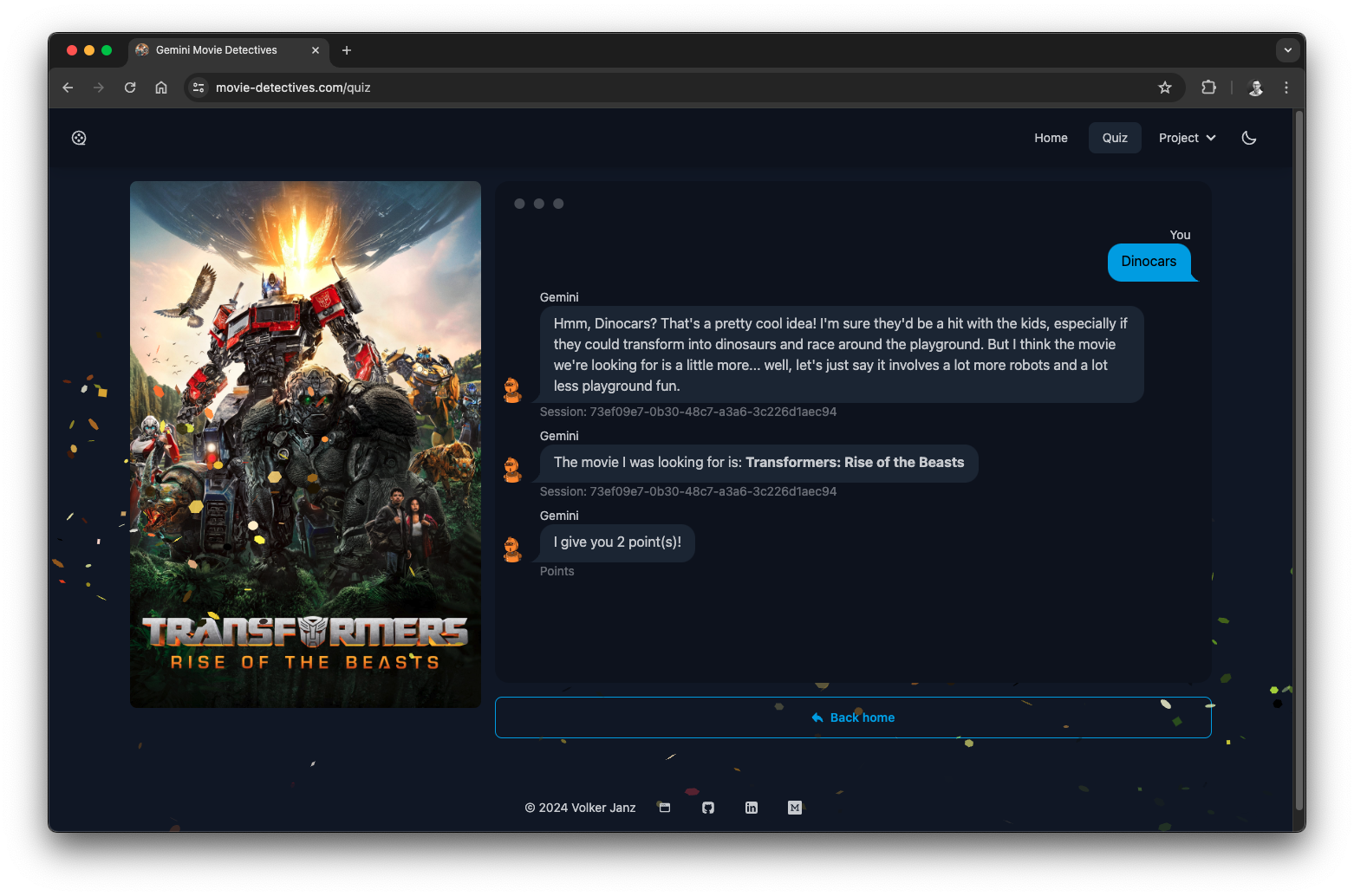
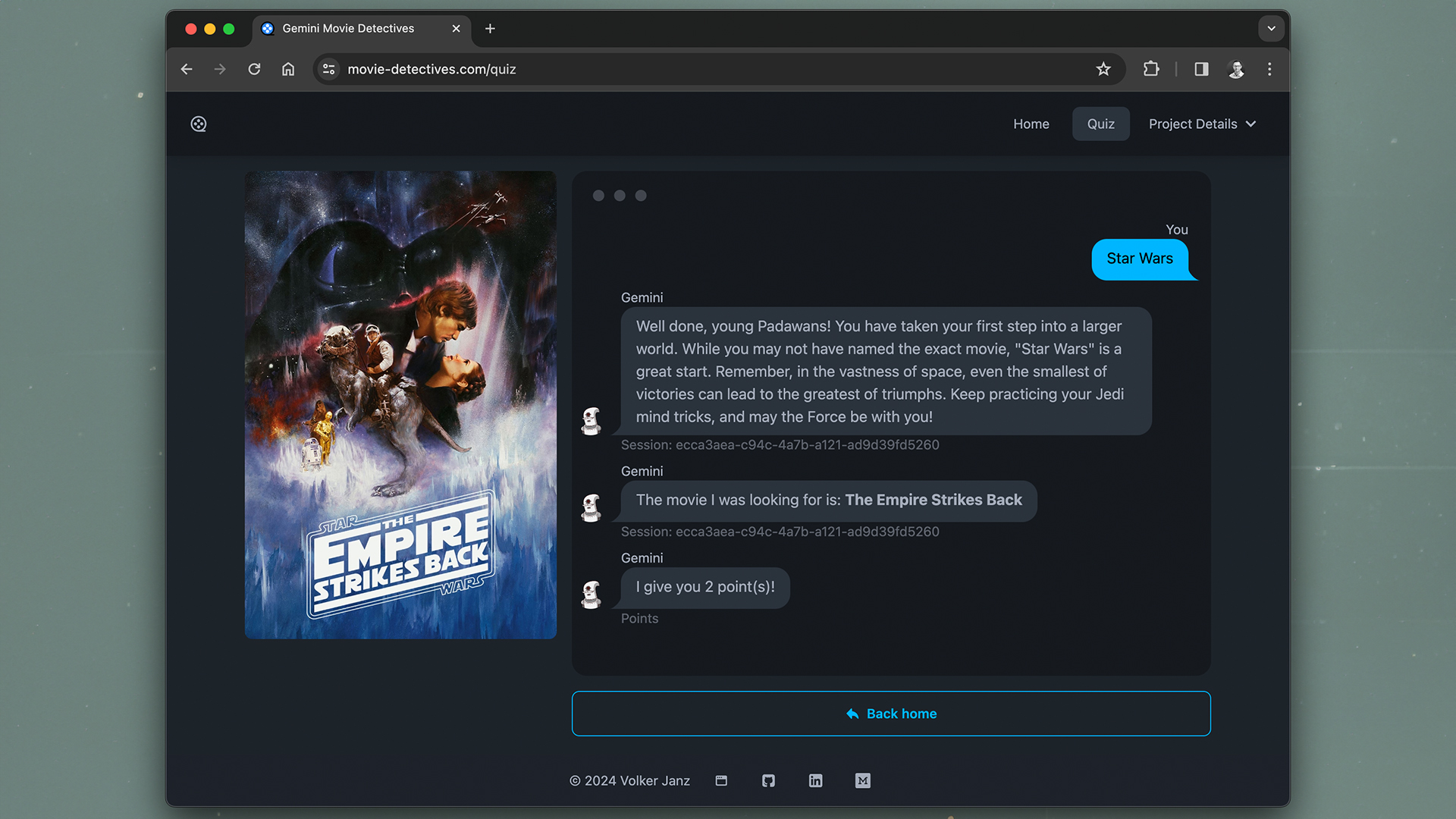
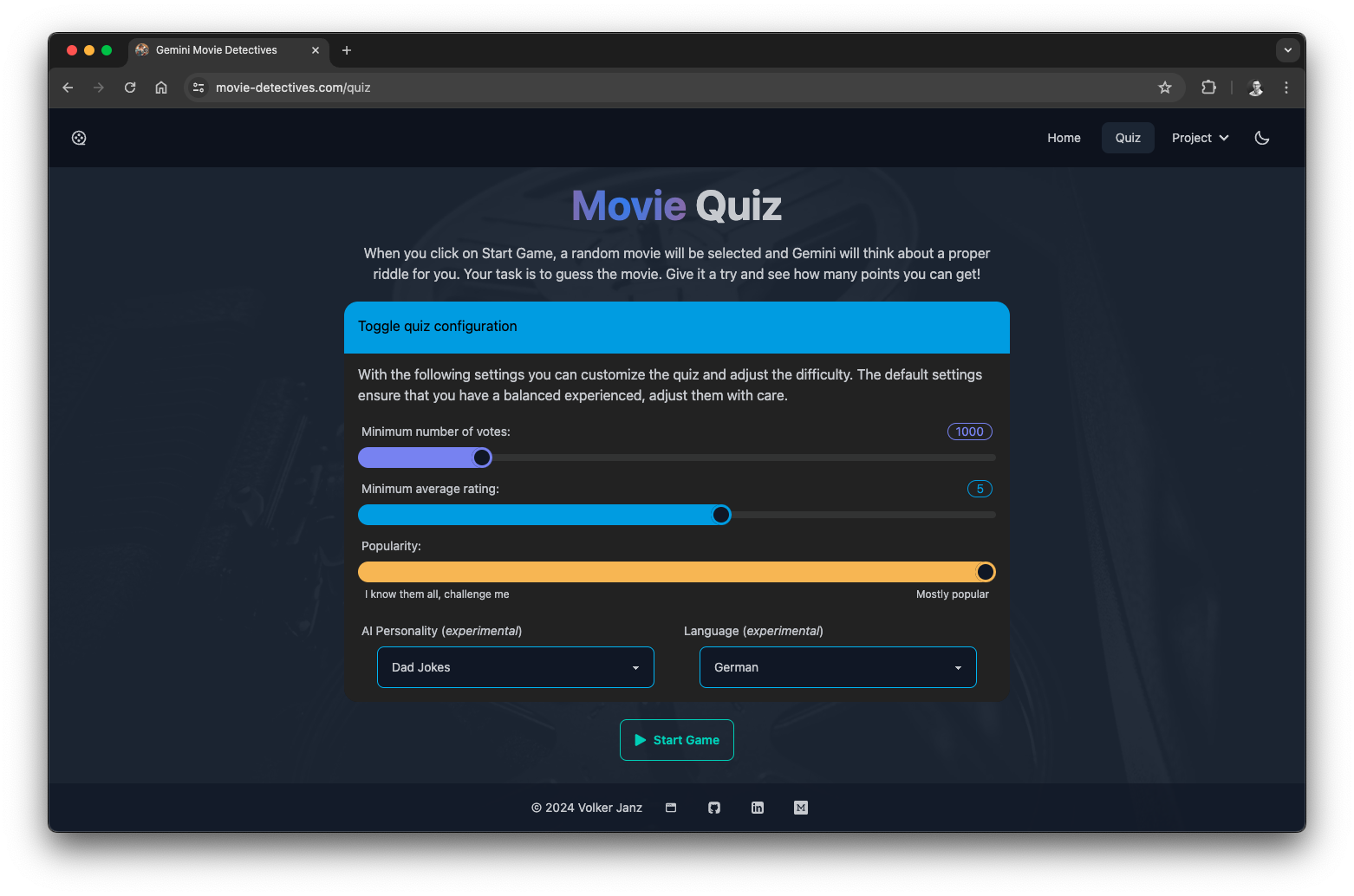
Quiz
The Quiz component displays the quiz itself and talks to the API via fetch. To create a quiz, it sends a POST request to api/quiz with the desired settings. The backend is then selecting a random movie based on the user settings, creates the prompt with the modular prompt generator, uses Gemini to generate the question and hints and finally returns everything back to the component so that the quiz can be rendered.
Additionally, each quiz gets a session ID assigned in the backend and is stored in a limited LRU cache.
Sessions
For debugging purposes, this component fetches data from the api/sessions endpoint. This returns all active sessions from the cache.
Stats
This component displays statistics about the service. However, so far there is only one category of data displayed, which is the quiz limit. To limit the costs for VertexAI and GCP usage in general, there is a daily limit of quiz sessions, which will reset with the first quiz of the next day. Data is retrieved form the api/limit endpoint.
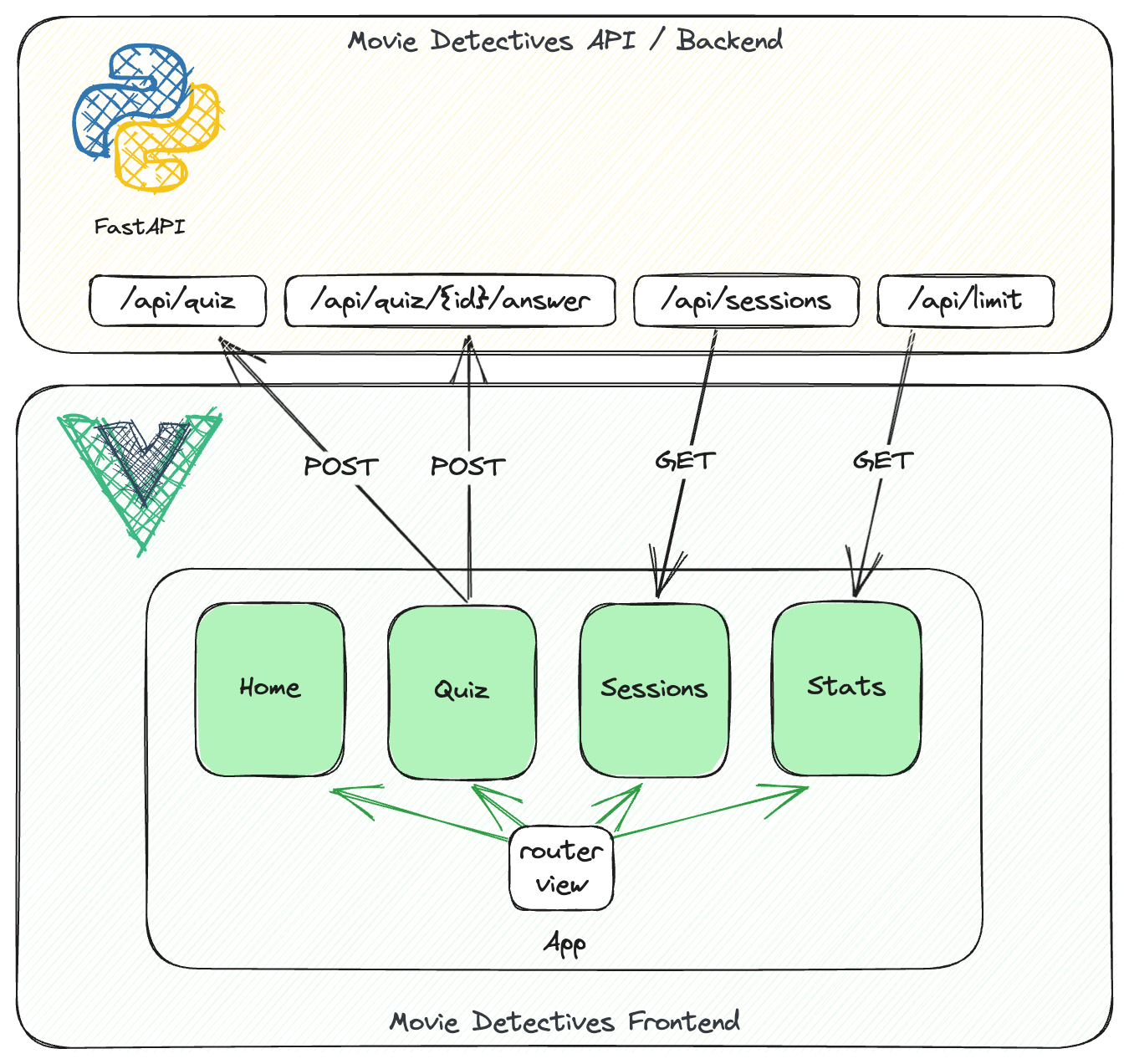 Movie Detectives - Vue Components
Movie Detectives - Vue Components
API usage
Of course using the frontend is a nice way to interact with the application, but it is also possible to just use the API.
The following example shows how to start a quiz via the API using the Santa Claus / Christmas personality:
curl -s -X POST https://movie-detectives.com/api/quiz \
-H 'Content-Type: application/json' \
-d '{"vote_avg_min": 5.0, "vote_count_min": 1000.0, "popularity": 3, "personality": "christmas"}' | jq .
{
"quiz_id": "e1d298c3-fcb0-4ebe-8836-a22a51f87dc6",
"question": {
"question": "Ho ho ho, this movie takes place in a world of dreams, just like the dreams children have on Christmas Eve after seeing Santa Claus! It's about a team who enters people's dreams to steal their secrets. Can you guess the movie? Merry Christmas!",
"hint1": "The main character is like a skilled elf, sneaking into people's minds instead of houses. ",
"hint2": "I_c_p_i_n "
},
"movie": {...}
}
Movie Detectives - Example: Santa Claus personality
This example shows how to change the language for a quiz:
curl -s -X POST https://movie-detectives.com/api/quiz \
-H 'Content-Type: application/json' \
-d '{"vote_avg_min": 5.0, "vote_count_min": 1000.0, "popularity": 3, "language": "german"}' | jq .
{
"quiz_id": "7f5f8cf5-4ded-42d3-a6f0-976e4f096c0e",
"question": {
"question": "Stellt euch vor, es gäbe riesige Monster, die auf der Erde herumtrampeln, als wäre es ein Spielplatz! Einer ist ein echtes Urviech, eine Art wandelnde Riesenechse mit einem Atem, der so heiß ist, dass er euer Toastbrot in Sekundenschnelle rösten könnte. Der andere ist ein gigantischer Affe, der so stark ist, dass er Bäume ausreißt wie Gänseblümchen. Und jetzt ratet mal, was passiert? Die beiden geraten aneinander, wie zwei Kinder, die sich um das letzte Stück Kuchen streiten! Wer wird wohl gewinnen, die Riesenechse oder der Superaffe? Das ist die Frage, die sich die ganze Welt stellt! ",
"hint1": "Der Film spielt in einer Zeit, in der Monster auf der Erde wandeln.",
"hint2": "G_dz_ll_ vs. K_ng "
},
"movie": {...}
}
And this is how to answer to a quiz via an API call:
curl -s -X POST https://movie-detectives.com/api/quiz/84c19425-c179-4198-9773-a8a1b71c9605/answer \
-H 'Content-Type: application/json' \
-d '{"answer": "Greenland"}' | jq .
{
"quiz_id": "84c19425-c179-4198-9773-a8a1b71c9605",
"question": {...},
"movie": {...},
"user_answer": "Greenland",
"result": {
"points": "3",
"answer": "Congratulations! You got it! Greenland is the movie we were looking for. You're like a human GPS, always finding the right way!"
}
}
⭐️ Accomplishments that I am proud of
There are four main outcomes that I am happy of:
- The product is actually fun to use. I enjoyed the movie quiz and I was impressed how much fun it was to try different personalities.
- Injecting up-to-date movie data into the prompt worked really well. The questions are accurate and facts Gemini integrates into the questions are correct and I can imagine how this can be very useful for educational games.
- Parts of the project can be used for other Gemini projects, like the modular prompt generator.
Last but not least, the most important aspect, this project is a proof of concept that Gemini can be used to create educational games with comparable low effort.
For me, this is a genuine game-changer. It's undeniable that teaching methods in schools and universities need updating to better meet the needs of today's students. The gaming industry is no longer a niche; it has surpassed the movie and music industries combined. However, integrating education with gaming always raises the question of how to cover development costs. Using a Large Language Model (LLM) makes this more manageable. Moreover, approaches like RAG reduce the risk associated with using LLMs for educational content significantly. We don't have to rely solely on multiple-choice questions or implement highly complex matching algorithms anymore; the AI can handle that, much like the interpretation of answers in Gemini Movie Detectives. Imagine populating a vector database with school books and documents to teach history lessons through an AI-generated RPG set in a historical context, or explaining math problems in the language of today's youth. Movie Detectives is more than a movie quiz game powered by AI; it represents a gateway to AI-driven educational content in schools and universities!
📚 What I've learned
- Combining up-to-date Python functionality with validation libraries like Pydantic is very powerful and can be used to ensure good data quality for LLM input.
- After I finished the basic project, adding more personalities and languages was so easy with the modular prompt approach, that I was impressed by the possibilities this opens up for game design and development. I could change this game from a pure educational game about movies, into a comedy trivia "You Don't Know Jack"-like game within a minute by adding another personality.
🚀 What's next for Gemini Movie Detectives
RAG improvements
Retrieval-augmented generation (RAG) is a technique for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge. The implementation in this project, is a lightweight version of this concept, but still external data (TMDB) is used to ensure accuracy and correctness of the generated quiz content.
This can be taken to the next level by leveraging a proper vector store (such as Qdrant) and create a much more sophisticated trivia / movie knowledge database to enrich the LLM generated content.
Extract modular prompt framework
The modular prompt framework has been instrumental in shaping the fun and dynamic nature of Movie Detectives. To extend its utility beyond my project, I'm planning to spin it off into an open-source tool. By incorporating advanced modularization techniques, I aim to make it a useful tool for other Gemini based projects. This could be especially useful, when it comes with well tested prompts for various personalities, languages and more.
Add more personalities, languages and movie data
With the modular prompt, it is an easy to extend aspect of the project. Adding more personalities and languages as well as movie metadata beyond TMDB, can grow it to a really fun service for movie enthusiasts.
Game improvements
Depending on the feedback to the game itself, there are various possibilities to improve Movie Detectives itself. Like a filter for a specific genre of movies, text-to-speech integration, Firebase integration to get a scoreboard and more sophisticated quiz sessions are just a selection of ideas.
Promote project for educational and trivia games
Back to the beginning: combining education with gaming is a great way, to utilize this technology for projects with high business value but also with a high value for the community, being able to reduce the effort of creating such educational content. It would be great to promote the project and work together with schools, universities or companies in this sector to use this in bigger projects.
⚠️ Instructions for Judges
The project is split into:
- Backend / API (Python + FastAPI): https://github.com/vojay-dev/gemini-movie-detectives-api
- Frontend (VueJS + Vite): https://github.com/vojay-dev/gemini-movie-detectives-ui
Setup Backend / API
Prerequisite:
- Python 3.12
- Poetry (see: https://python-poetry.org/docs/#installation for installation instructions)
- The Movie Database (TMDB) API Key (provided via mail)
- GCP Service Account to use Gemini via VertexAI (provided via mail)
Checkout and switch to project root:
git clone git@github.com:vojay-dev/gemini-movie-detectives-api.git
cd gemini-movie-detectives-api
Configure poetry to use in-project virtualenvs:
poetry config virtualenvs.in-project true
Install dependencies:
poetry install
Configuration:
The API is configured via environment variables. If a .env file is present in the project root, it will be loaded
automatically. Create a .env file in the project root with the following content:
TMDB_API_KEY=<insert TMDB API key here>
GCP_PROJECT_ID=vojay-329716
GCP_LOCATION=us-central1
GCP_SERVICE_ACCOUNT_FILE=gcp-vojay-gemini.json
GCP_GEMINI_MODEL=gemini-experimental
Of course you can set GCP_GEMINI_MODEL to any other model which is available via API, such as gemini-1.0-pro. But I enjoyed exploring the experimental model, since quiz questions and answer interpretations are even more natural, so I recommend to try that one out.
The Service Account file gcp-vojay-gemini.json was provided via mail and must also be placed in the project root.
Run:
The following commands assume that the virtual environment created by Poetry was set up in the project root in .venv/.
source .venv/bin/activate
uvicorn gemini_movie_detectives_api.main:app --reload
Test API call:
Run the following curl command to ensure the API is running:
curl -s localhost:8000/movies
It will simply get a list of movies.
Setup Frontend
Prerequisite:
- Node.js version 18+
- NPM
- Backend / API must be running as described above
Checkout and switch to project root:
git clone git@github.com:vojay-dev/gemini-movie-detectives-ui.git
cd gemini-movie-detectives-ui
Install dependencies:
npm install
Configuration:
The Frontend is already configured to use the API running at localhost. However, it is recommended to double check the
configuration in src/config.js. Here API_BASE_URI must be match the host and port the API is running on. For the local
default setup, this is:
export const API_BASE_URI = 'http://localhost:8000'
Run:
npm run dev
You can now open up the Frontend at: http://localhost:5173/ in your browser (or simply click the link provided by Vite in the logs).
Have fun 😉!
Alternative
The project is also up and running at: https://movie-detectives.com/
🚦 Testing
The Gemini client (GeminiClient) as well as the modular prompt generator (PromptGenerator) are covered by unit tests.
The tests are implemented using the unittest Python module. Simply execute the following command to run the tests, once the virtual environment is active:
python -m unittest -v
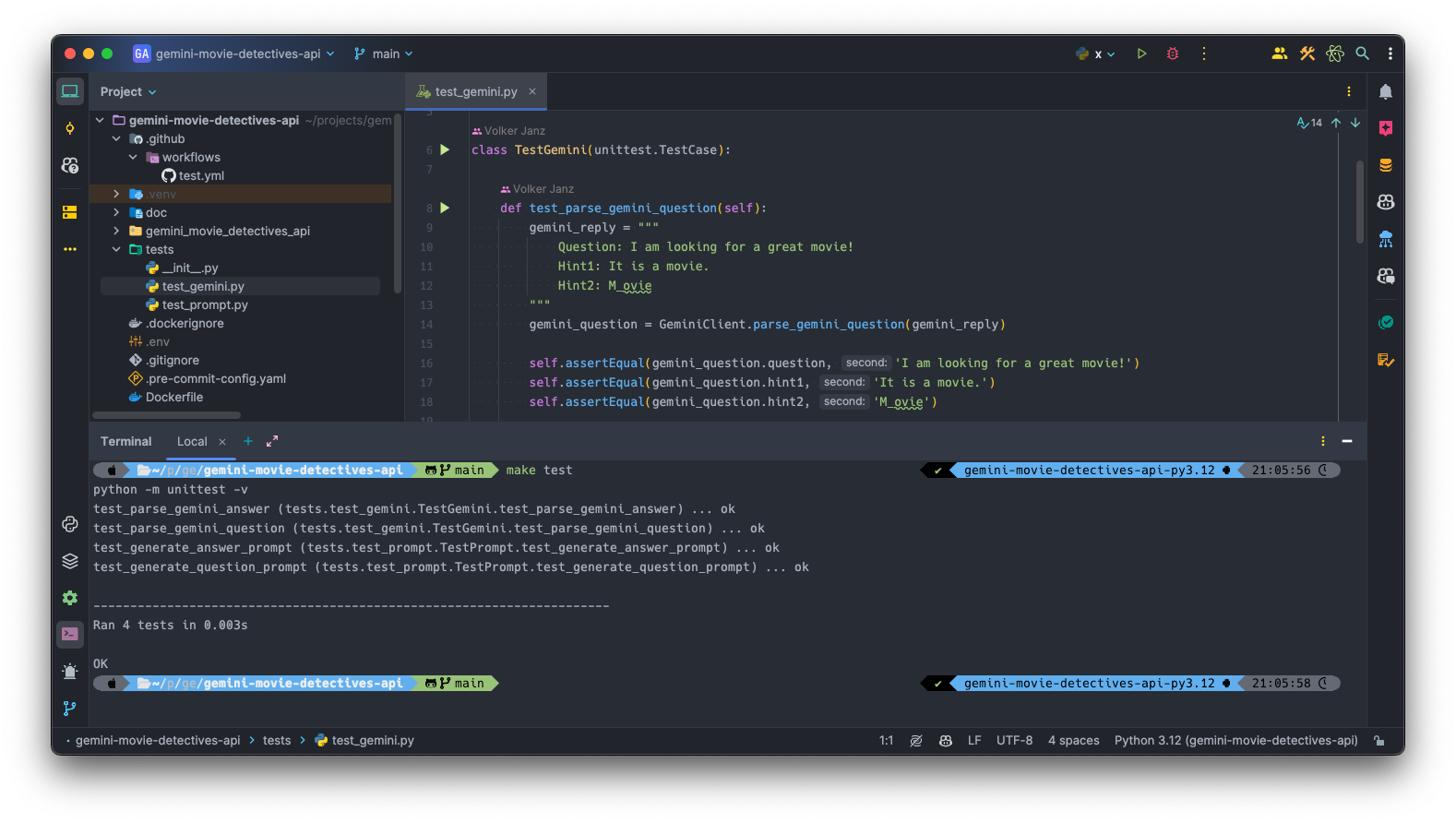
The tests as well as the linter are exectued automatially on every commit via Github actions (see: .github/workflows/test.yml in the API project).
Have fun with Gemini Movie Detectives and I am looking forward to more AI-driven educational content.
![]()
Built With
- daisyui
- docker
- fastapi
- gemini
- google-cloud
- httpx
- javascript
- jinja
- poetry
- pre-commit
- pydantic
- python
- ruff
- tailwindcss
- tmdb
- vertexai
- vite
- vuejs

Log in or sign up for Devpost to join the conversation.