


Inspiration 💡
The introduction of Large Language Models (LLMs) has the potential to bring about tremendous change in the work lives of future knowledge workers around the world. As current students ourselves, we reflect on our formative years in school and wonder how our educational experience might have been different if we had access to a 100-trillion parameter machine learning model on command. Would it have impacted our understanding of various topics? We are concerned about children born today and in the future, who will grow up in a world filled with intelligent artificial agents.
The advent of LLMs promises to revolutionize education by offering personalized tutoring experiences for children. By effectively understanding and responding to each child's unique learning needs, LLMs can foster a deeper exploration of curiosity and pave the way for mastery learning.
To comprehend the impact of LLMs on education, it's essential to analyze various aspects:
Individualized Learning Paths: Customization allows children to engage with topics they're passionate about and ensures they receive the right level of challenge, preventing boredom or frustration.
Instant Feedback: LLMs can provide immediate feedback on a child's performance, helping them identify areas for improvement and consolidate their understanding. This timely intervention facilitates a more efficient learning process and encourages children to learn from their mistakes.
Availability and Accessibility: LLMs enable learning experiences that transcend traditional time and space constraints. Children can access personalized tutoring anytime, anywhere, and at their own pace, allowing them to learn more effectively and comfortably.
However, as with all good things, we understand the need for balance. We believe parents should have the final say in their children's interactions with LLMs. Parents must have control over the outputs of LLMs to monitor their child's mental headspace, the influences they are exposed to, and whether the technology is supporting or hindering their education. Providing parents with oversight over LLM responses to minors ensures that the potential risks of one-size-fits-all chatbot systems are mitigated, resulting in a more tailored and supportive learning experience.
We believe the core problem to be solved in the interaction of kids with LLMs is the absence of LLMs configured for children, a friendly user interface that kids would enjoy, and a lack of parental awareness about the type of responses being sent to kids when they use LLMs.
We are excited to introduce GPTeddy - the lovable, huggable, and conversationally adept teddy bear, designed to accompany children from ages 3 to 7 on their journey of learning and growth.

What it does 🤔
GPTeddy is a system comprised of two components: a Soft teddy bear fitted with a Raspberry Pi, microphone, and speaker as well as a software client that allows parents to regulate the conversations kids have with the LLMs.
an interactive, educational companion that provides a safety-ensured dip into expanding their knowledge from the comfort of their homes. It is based on a teddy bear, which has been modified to include hardware and software to provide full talking capability based on interaction with children. It also includes parental controls to help personalize and safely guide children through their learning journey, as well as analytics to help document their progress visually.
 ](https://postimg.cc/FdFzmbg2)
](https://postimg.cc/FdFzmbg2)
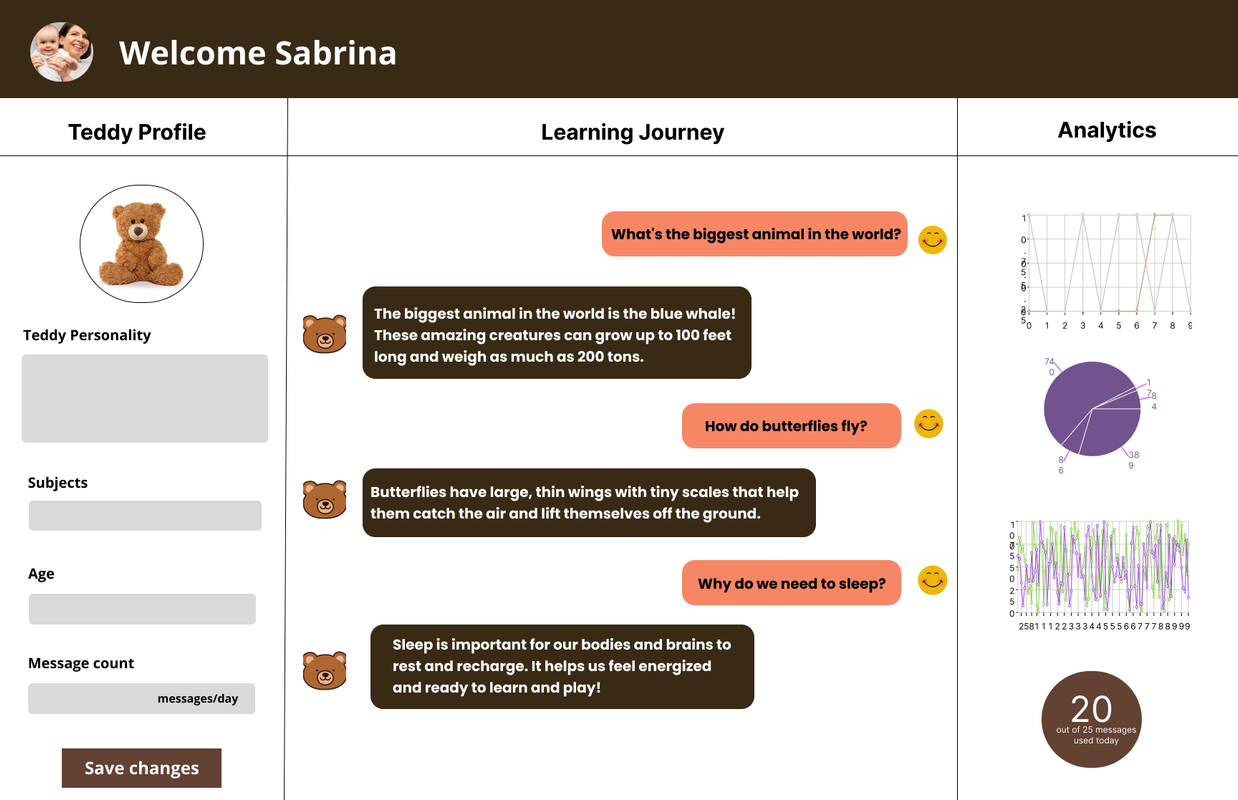
As seen from the layout of the web app, there are options for the parent to set options for their children. Right next to that, there is also a visual transcription of the conversation between the child and GPTeddy. Next to that, there is a column for the analytics of the child's learning progress. This is useful for helping identify where the child may need help and how to aid them in building their confidence.

Building the web-app and final product involved interfacing between hardware and software. The diagram above details the various technologies we used. For our back-end and cloud services, we had a strong focus on Microsoft Azure and implemented many features. We also focused on Cohere for implementation for our cloud-services as well. In addition to these, we tied them in with our hardware. This consisted of a Raspberry Pi along with microphone to detect speech (speech to text) and speaker for amplification (speech to text). With a battery pack, we put these in the teddy bear and thereby created GPTeddy as well as an interactive web application. Our main goal was to create a safe, educational companion while reaching children and putting a smile on their face.
Home Room Track Prize🏫
As we embark on the journey to create a project that enriches academic environments, we firmly believe that GPTeddy, an innovative and educational teddy bear for children aged 3 to 7, is a game-changer that truly deserves to win. Here's why:
Bridging the gap between technology and early education: GPTeddy seamlessly integrates advanced speech-to-text, text-to-speech, and GPT API capabilities with a beloved children's toy - the teddy bear. This amalgamation offers an interactive and engaging learning experience for young children while fostering their emotional attachment and curiosity.
Personalized learning experience: GPTeddy caters to each child's unique learning needs and preferences, ensuring a tailored educational journey. By facilitating one-on-one conversations, it encourages children to explore their interests, ask questions, and learn at their own pace, all while enjoying the comforting presence of their cuddly companion.
Parental involvement and oversight: GPTeddy's software client is designed with a strong emphasis on parental controls. It records all conversations between the child and GPTeddy, allowing parents to monitor and review their child's interactions. This feature enables parents to maintain a safe and age-appropriate learning environment while ensuring that their child's education is being effectively supported.
Ease of implementation and affordability: Running on a Raspberry Pi, GPTeddy offers a cost-effective and easily accessible solution for families. Its compact and user-friendly design makes it an attractive addition to children's bedrooms, playrooms, or any space where learning and play converge.
Adaptability and long-term impact: GPTeddy has the potential to grow with a child, adapting to their evolving needs as they progress through their early years of education. By nurturing a love for learning, fostering curiosity, and providing a safe and controlled educational experience, GPTeddy has a lasting impact on a child's overall development.
In conclusion, GPTeddy exemplifies the perfect fusion of technology, education, and emotional connection. By providing a personalized learning experience, promoting parental involvement, and prioritizing safety and adaptability, it sets the stage for a brighter future for our children. GPTeddy is not only a winning project but a stepping stone toward redefining early education and a worthy investment in the leaders of tomorrow.

Cohere Challenge 🧮
We also extensively used Cohere's API to help develop the cloud services for our product.
Cohere powered out impressive AI-performance, transforming Teddy from a once lifeless teddy bear to an almost-all knowing, friendly, and interactive agent that allows everyone to learn faster. Let's systematically run through how Cohere fueled our build and why we believe we deserve to win the CoHere prize.
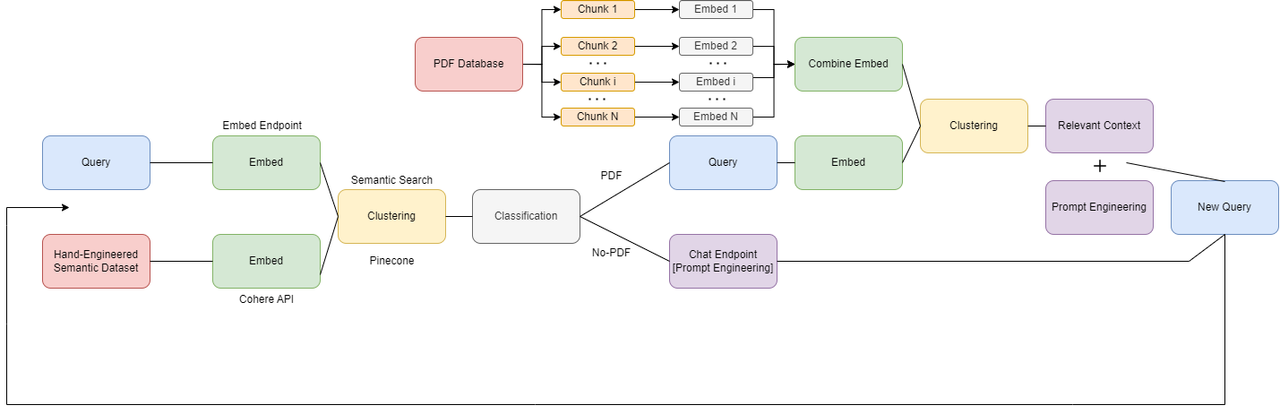
- Embeddings We use the Cohere Embedding API to quickly encode three different modalities of information: text queries from users, a manually designed dataset of input questions and types, and finally, textual input through PDF Files. Let's explore how each of these works.
- Text Queries: We embed each question from the user into a 4096 dimensional vector. This allows us to extract the true meaning behind a user's question and use that to more accurately serve their needs.
- Question Category: This is a cool and interesting application. We created a manual dataset of 20 common phrases that might be suggestive of a question that the chatbot should answer via general knowledge and 20 phrases that are suggestive of a question that the chatbot should answer using the input PDF files as context. We encode every single one of these questions into 4096 vector embeddings and use them to perform a semantic search that allows us to match an input query's embeddings to the top k most similar pairs in our input dataset, much like a standard K-means clustering algorithm. Then, we simply assign the queries's class label to the class mode (default/PDF) that appears more frequently amongst the matched results. Setting this classification label, in turn, powers our conditional branches that allow us to treat PDF and non-PDF conditioned prompts separately - boosting our overall performance.
- PDF Encodings: Similar to how we encode our training dataset, we also encode pdf files for which we want to support context. The main difference with our approach here is that PDFs are large and therefore, must, be chunked up into smaller subsections in order to be encoded properly within the models 4096 token local memory. Specifically, we break each pdf into subsections that about 500 tokens long each. Each of these subsections are encoded along with metadata including the page number, exact words, and citation info. At inference-time, we once again run semantic search between the input user queries and the context embeddings. Context for the top-5 matching embeddings are added on to the prompts, resulting in highly intelligible querying.
- NOTE: As close readers might have noticed, computing these embeddings for large datasets like our entire pdf files and our K-means training dataset can be expensive. Therefore, we take advantage of vector databases like Pinecone, which allow us to store generated embeddings long-term and query them quickly and efficiently for semantic search and clustering.
- Clustering and Semantic Search: Semantic search plays a really important role in allowing us to make the most out of our embeddings. We match information in our optimized embedding space, which allows us to capitalize on rich contextual relationships between our input text. Cohere and Pinecone's interfaces made our semantic searching experiences easier and fruitful.
- Classification: We tried to push the bounds of what we could do in a zero-shot manner by framing regular classification as an embedding similarity problem. Specifically, instead of training on a large dataset of pro/anti-PDF prompts, we leveraged the fact that in our embedding space, few-shot learning can provide us 95% of the gains at a fraction of the compute, time, and cost. Ultimately, although we cover it under embeddings, categorizing input queries is funamentally a classification problem.
- Text Generation: Few would disagree with the fact that it's GPTeddy's chat-bot like/generational abilities that bring it alive. Specifically, Cohere's chat and generate endpoints power an omnipotent educational chatbot that makes GPTeddy the coolest, smartest, and kindest stuffed toy to ever exist. Of course, not all of this came instantly. A lot of GPTeddy's performance comes from iterative and extensive prompt-engineering from our team. Especially, when we couple this with distinct workflows, varied knowledge sources, we build a graph architecture that is repeatable, adorable, and huggable :hug:
- Short-term Conversational Memory: Cohere's native chat sdk supports a circular buffer, which allows us to maintain context for our past conversations. This is super useful as it makes it seem like GPTeedy is actually listening to you and cares enough to remember your conversation.
- Long-term Memory: Pinecone coupled with Cohere makes everything awesome and ephemeral about GPTeddy sustainble for a long, long time. It saves us compute, money, and time - all while making our performance better.
Best Use of Microsoft Cloud for Your Community👩🏻💻
GPTeddy is a smart teddy bear designed for children aged 3 to 7 that provides personalized tutoring and promotes a safe and interactive learning environment. The teddy bear is equipped with speech-to-text and text-to-speech capabilities, as well as integration with the GPT API. Running on a Raspberry Pi, GPTeddy offers an affordable, accessible, and enjoyable learning experience for young children. Additionally, a software client with parental controls enables parents to monitor and review their child's interactions with the teddy bear, ensuring a safe and age-appropriate learning experience. Azure services were used top to bottom so scale a data and workload intensive application like GPTeddy, We used
1.) CloudSQl- Postgres Instance linked to the Web app+Database Solution deployed using azure. https://learn.microsoft.com/en-us/azure/app-service/tutorial-python-postgresql-app
2.) AzureCache - stream cache for websockets. django-channels required a snappy fast cacheing backend for supporting the network of websockets. AzurCache came in handy.
3.) App service for django deployments Used the ready out of the box deployment solution https://learn.microsoft.com/en-us/azure/app-service/tutorial-python-postgresql-app provided by azure , this was fairly interesting .
4.) Blob storage for hosting the frontend website as well as static files and images. The react website was built and uploaded to static hosting on a public blog storage which was a very simple deployment.
5.) Virtual Machine For custom machine learning and application deployments as well as django related apis.
5.) DNS hosted zones and VPC that azure built conveniently for us.
6.) Speech to text and Text to speech was a huge highlight of convenience and accuracy to us and simplified 2 of our major problems.
7.) We also used the speech synthesizer to support voice modulations.
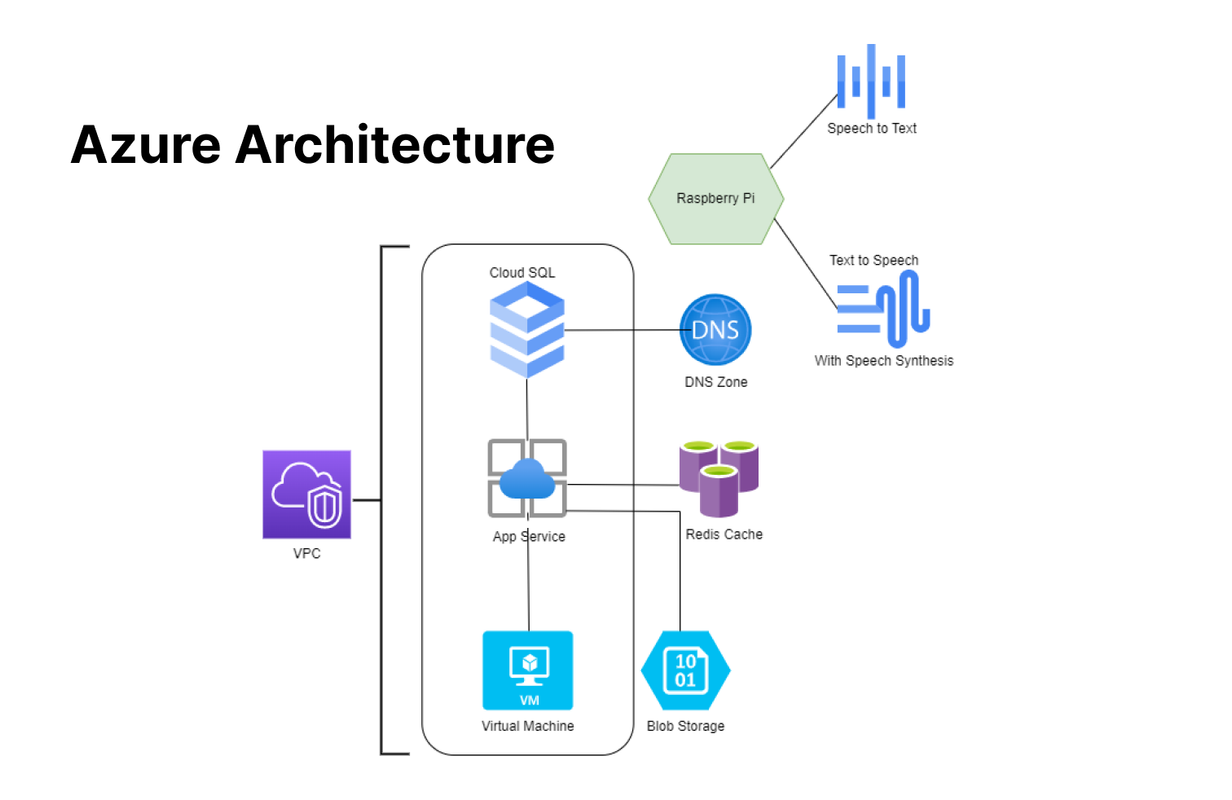
To understand further please have a look at our reference architecture
How azure helped us make a better product ?
Out of the box speech to text and text to speech with a flawless recognition rate was a direct winner for our products priorities
The VM instances and app service deployments were almost no-code which gave us an edge over in the speed of development.
Microsofts easy to use console was one of the most simplifying factors , the reference architectures in the marketplace helped us configure a complete service layout at one go.
Deployments using github actions simplified our workflow enabling the frontend person to get superfast deployments in no time
We will harness the power of the Microsoft Cloud to further enhance GPTeddy's functionality and positively impact the community. Here's how:
Azure Web App Service: We will utilize Azure Web App Service to build and deploy a full-stack web app that serves as the parental control panel. Parents can access this platform to monitor their child's progress, customize the learning content, and review the conversations between their child and GPTeddy.
Azure Speech Synthesizer and Speech Recognition: Giving voice to the teddy would have been really difficult without the out-of-the-box functionalities that Azure provides.
Github Action Deployment Pipeline - The app service built-in integrations with github actions helped us scale as mentioned earlier
By implementing these Microsoft Cloud services, we will optimize GPTeddy's potential to transform early childhood education and positively impact the community. Our project addresses a social impact issue by providing young children with an engaging, personalized, and secure learning experience. In doing so, we invest in our future leaders and contribute to a brighter tomorrow.
We incorporated several Microsoft Cloud services when developing our project. These played a major role in the back-end and cloud-based services for GPTeddy. Following the workflow as seen in our diagram above, we used Cloud SQL, the Azure App Services and Virtual Machine all falling under VPC, along with DNS Zone, Redis Cache, and Blob Storage. For the speaker/mic combination with the Raspberry Pi, we also equipped Azure's speech to text and text to speech conversion (with speech synthesis for the voice) for communication with GPTeddy.
How we built it ⚙️
The whole process can be broken into the following points :-
React, Tawilwind on the frontend
Python Django, Sockets
External services like Azure, Auth0m Co:here.ai
Design 🎨
We were heavily inspired by the revised version of Double Diamond design process, which not only includes visual design, but a full-fledged research cycle in which you must discover and define your problem before tackling your solution & then finally deploy it.
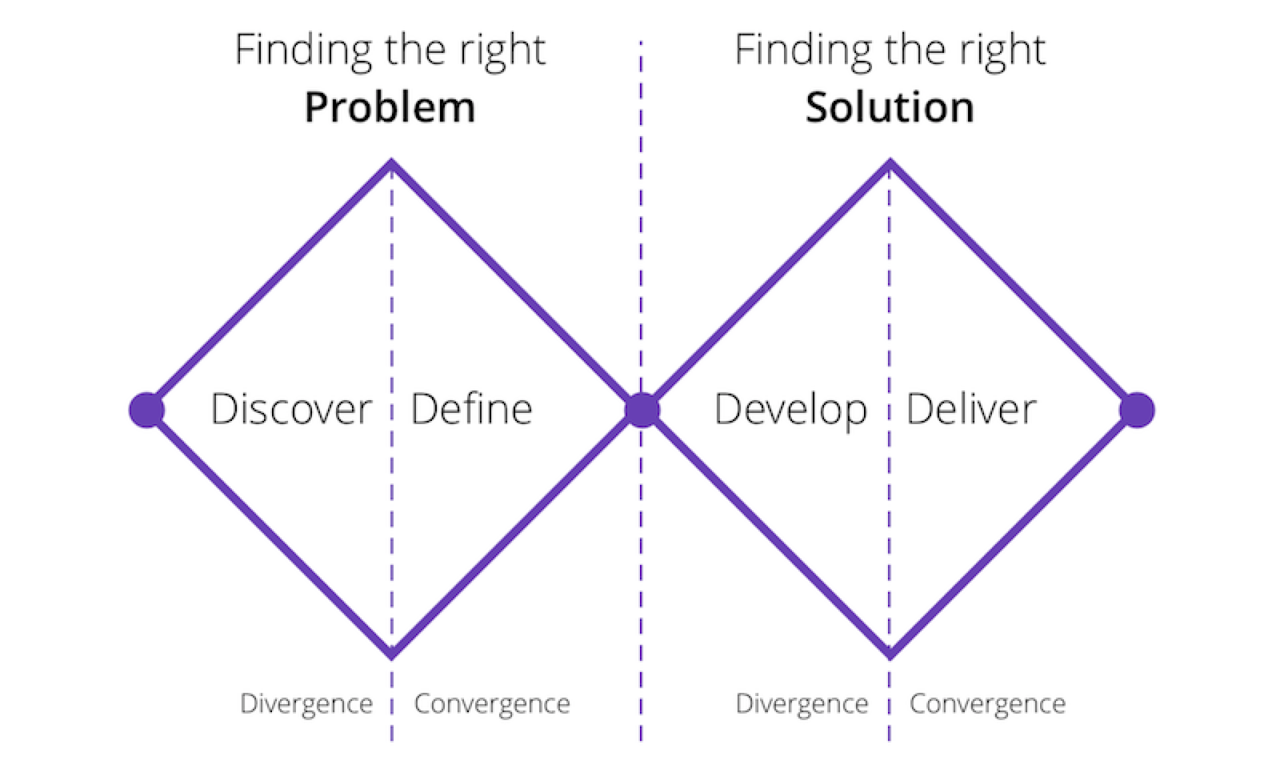
Discover: a deep dive into the problem we are trying to solve.
Define: synthesizing the information from the discovery phase into a problem definition.
Develop: think up solutions to the problem.
Deliver: pick the best solution and build that.
Moreover, we utilized design tools like Figma, Photoshop & Illustrator to prototype our designs before doing any coding. Through this, we are able to get iterative feedback so that we spend less time re-writing code.

Research 📚
Research is the key to empathizing with users: we found our specific user group early and that paves the way for our whole project. Here are a few of the resources that were helpful to us —
Microsoft-reference-architectures and case studies :- https://learn.microsoft.com/en-us/azure/architecture/browse/
Azure guides - https://learn.microsoft.com/en-us/azure/app-service/tutorial-python-postgresql-app?pivots=deploy-portal&tabs=flask%2Cwindows
Setting up Raspberry Pi (https://beebom.com/how-setup-raspberry-pi-without-monitor-ethernet-cable/), (https://www.instructables.com/How-to-Use-Mobile-Hotspot-to-View-Raspberry-Pi-Des/)**
CREDITS
Design Resources : Freepik, Behance
Icons : Icons8, fontawesome
Font : Urbanist / Roboto / Raleway
What we learned 🙌
Proper sleep is very important! :p Well, a lot of things, both summed up in technical & non-technical sides. Also not to mention, we enhanced our googling and Stackoverflow searching skills during the hackathon :)
Built With
- azure
- cohere
- django
- python
- raspberry-pi
- react.js






Log in or sign up for Devpost to join the conversation.